
I have to start by saying I’m a massive fan of AI. I’ve used it over the last few years as a foundational tool. From accelerating complex coding workflows and distilling hours of meeting notes to generating acceptance criteria for new features. The value it’s added has been genuinely disruptive. In fact, our team has been so efficiently enabled that we’ve found the time to properly re-architect core systems and handle long-term technical debt, all while exceeding our business objectives.
Almost every company, across every industry is experiencing this exact efficiency surge right now.
It’s incredible, but the sheer scale of this demand comes with a massive, hidden cost to the environment in the form of many new and proposed AI data centers.
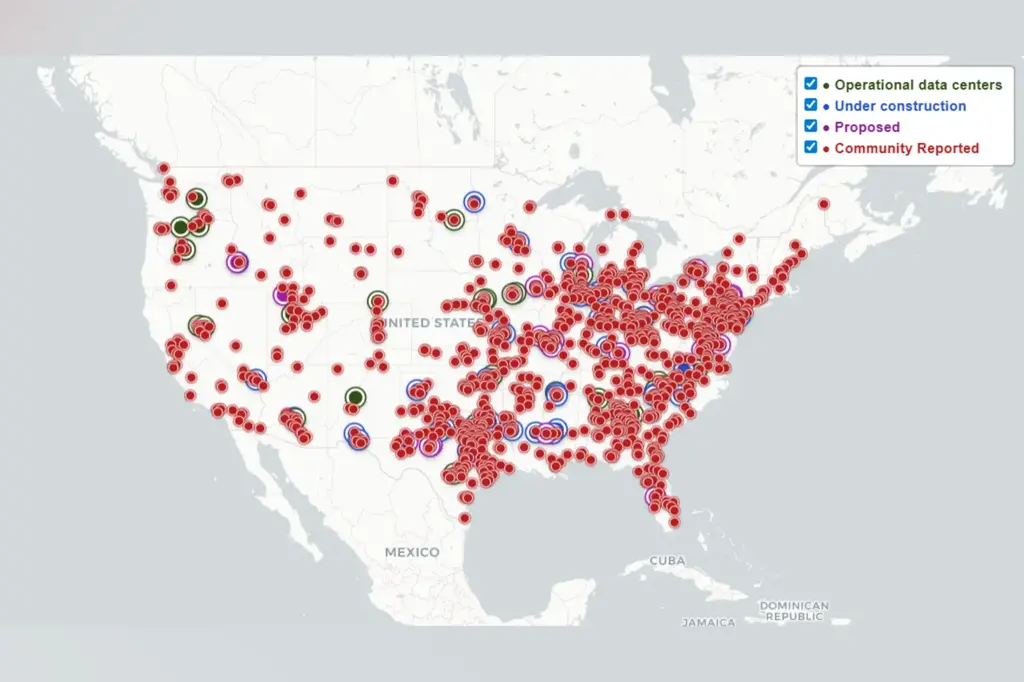
Source: Brockovich AI Data Center Reporting
When we talk about AI, we forget to talk about the power. To meet the unrelenting demand of constant data processing, countless AI data centers are being proposed and built across the United States and beyond. This infrastructure build-out is more than just a matter of cables and servers; it’s stressing already fragile power grids, driving up consumer electricity costs, contributing to local noise pollution for surrounding communities, and, critically, generating a type of harmful groundwater runoff that can seep right back into the local water supply.
I’ve been tracking these effects for years, but some of the impacts have only become starkly clear recently.
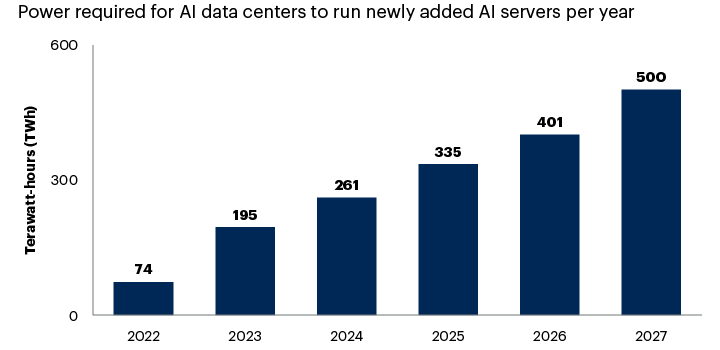
Source: Gartner Study
For these reasons, I’ve become a major advocate for running open-source models locally. When we run them on our own machines, we bypass the massive energy draw and infrastructure footprint of centralized AI data centers. And yes, there’s a huge bonus benefit: we keep our data and proprietary context entirely within our control, never sending it to a third party for potential training or storage.
So, my team and I have adopted a conscious approach: we run local models as much as our workflow allows. For non-coding tasks, we use a curated selection of open-source models. These are “quantized” versions which, in layman’s terms, means they’ve been optimized and “watered down” just enough to run efficiently on machines with less RAM. The results are genuinely impressive; the difference from the full-sized, paid models is often hard to detect in practice.
We’ve also found success with local coding tools using VS Code extensions like Continue, comparing them against paid models through Copilot or Claude Code.
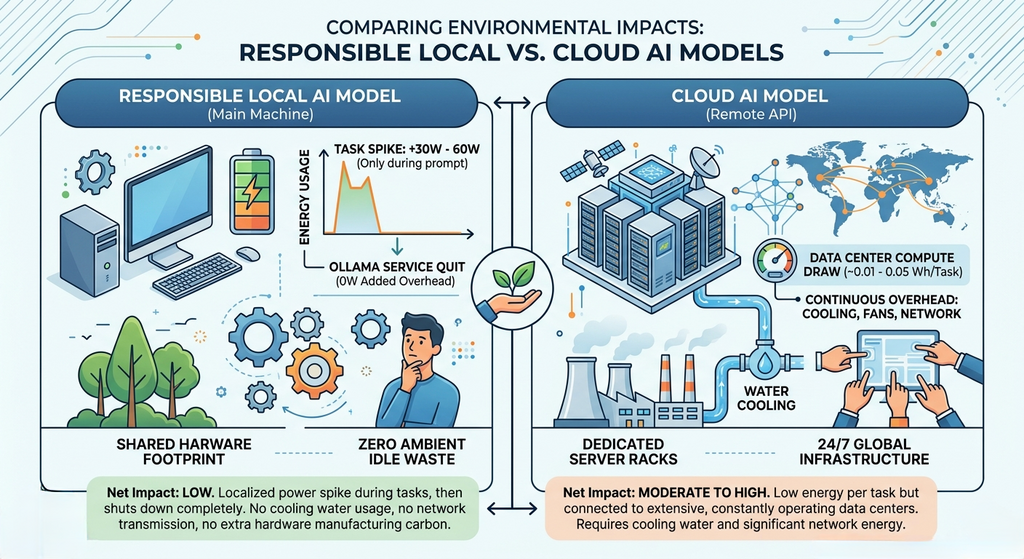
Source: Comparative environmental impact data synthesized from the official Google Cloud AI Inference Environmental Impact Study, foundational Google Sustainability Reports, and community hardware benchmarks for localized edge GPU inference power consumption.
However, in my opinion as of today the comparison is clear: the paid, cloud models are faster, they accept more input context, they handle complex agentic tasks like automatically modifying code or deeply reading multiple files better, and they generally provide a higher degree of consistency and reliability. While local open-source models do work, they currently require more patience and hand-holding from the user. Hopefully, advancements in model optimization and better local vectorization techniques in libraries like Continue will soon close that gap.
But even when we use the paid services, we are making conscious choices. I always default to the smallest possible model for the job, like Claude Haiku, simply to limit token usage and, critically, minimize our shared environmental footprint.
The resource problem isn’t always an infrastructure one; sometimes it’s a management one. I’ve heard stories of senior leaders judging employees on the sheer number of cloud tokens they use to measure productivity. In my view, this approach is flawed. It penalizes caution and efficiency. Instead of measuring the volume of consumption, it fails to reward the smart, responsible use of local and cloud resources.
AI is not going away. The genie is out of the bottle. It is a powerful, transformative force. But that transformative power comes with a choice.
We cannot afford to treat it as a limitless, consequence-free resource. The industry must realize that efficiency can no longer mean environmental sacrifice.
The good news is that the choice is literally in our hands.
We have the power, as users, to push for better infrastructure, demand transparent carbon reporting from our providers, and—most importantly—aggressively adopt local, open-source alternatives wherever our use case allows.
Let’s commit to demanding responsible AI. Let’s make sustainable computation the new gold standard. We can all save the planet, one prompt at a time.
Leave a Reply